Hive QL的那篇暂时不更2333,因为现在工作的公司不用Hive,主要使用云数据库BigQuery~
SQL语句执行顺序
这个本该在第一天学sql的时候就更新的,结果到现在才开始试图理清这个关系,正在自我反省中~
1 | -- 源自知乎https://zhuanlan.zhihu.com/p/77847158 |
SQL优化
| 核心思想 | 常用方法 |
|---|---|
| 最大化利用索引 | 减少数据访问 |
| 尽可能避免全表扫描 | 返回更少的数据 |
| 减少无效数据的查询 | 减少交互次数(批量DML操作) |
| 减少服务器 CPU 开销 | |
| 利用更多资源(使用表分区) |
查询索引失效情况
- 避免字段开头模糊查询,如果开头一定要使用模糊查询,可以尝试使用判断是否包含子串的instr函数
- 避免使用 in 和 not in,可以使用exists或者between and来代替
- 避免使用 or,可以使用union代替
- 避免进行 null 值的判断
- 避免在 where 条件中等号的左侧进行表达式、函数操作,比如time=和date(time)=,一个是靠索引一个走全表
- 数据量大时,避免使用 where 1=1 的条件
- 索引列查询条件避免使用 <> 或者 !=
- where 条件仅包含复合索引非前置列,例如联合索引包含 key_part1,key_part2,key_part3 三列,但 SQL 语句没有包含索引前置列”key_part1”,按照 MySQL 联合索引的最左匹配原则,不会走联合索引
- 隐式类型转换造成不使用索引,例如索引列是varchar类型,但是判断写成=123,这样不会走索引
- order by 条件要与 where 中条件一致,否则 order by 不会利用索引进行排序,单纯order by不会走索引
查询条件优化
- 复杂查询,使用中间临时表暂存数据
- 优化 group by 语句
- 优化 join 语句,使用join来代替子查询,因为join不需要在内存中创建临时表
- 优化 union 查询,除非确实要消除重复行,否则建议使用union all,因为union默认distinct,会对整个临时表的数据做唯一性校验,这样做的消耗很高
- 拆分复杂 SQL 为多个小 SQL,避免大事务
- 使用 truncate 代替 delete
- 使用合理的分页方式以提高分页效率
建表优化
- 在表中建立索引,优先考虑 where、order by 使用到的字段
- 尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销
- 查询数据量大的表会造成查询缓慢,主要的原因是扫描行数过多,可以通过程序,分段分页进行查询,循环遍历,将结果合并处理进行展示
- 用 varchar/nvarchar 代替 char/nchar,因为变长字段存储空间小
DML优化
- 批量插入数据
- 适当使用 commit,可以释放事务占用的资源而减少消耗
- 避免重复查询更新的数据
- 查询优先还是更新(insert、update、delete)优先
其他优化
- *避免select **
- 避免出现不确定结果的函数,例如now()、rand()、sysdate()、current_user()使用可能会导致数据不一致,专门针对与迁移数据库或者复制数据库的情况
- 多表关联查询时,小表在前,大表在后,因为from后表关联查询是从左至右的,第一张表会涉及到全表扫描
- 使用表的别名,减少解析的时间并减少哪些友列名歧义引起的语法错误
- where 字句替换having 字句,where是在group之前的操作,可以通过where限制group by操作的记录数目
- 调整 where 字句中的连接顺序,mysql是从左往右,自上而下的顺序解析 where 子句。根据这个原理,应将过滤数据多的条件往前放,最快速度缩小结果集
unnest 数组转行
目前的数据结构主要使用数组+结构体键值对(key,value)的形式,即数组元素是键值对,一贯先使用
1 | left join unnest(properties) p |
然后使用
1 | MAX(IF(p.key = 'xxx',CONCAT(ifnull(p.string_value,''),ifnull(CAST(p.int_value AS string),''),ifnull(CAST(p.float_value AS string),''),ifnull(CAST(p.bool_value AS string),'')),NULL)) |
返回null表示没有这个键/字段,返回’’表示这个键/字段为null
同理,如果是需要取某个满足特定条件的字段值,可以使用if或者case when,但不能直接group by这个结果,因为其他字段会变成null,应该使用max(if(…))来实现这个功能
cast 强制类型转换
null转成任意类型后的值仍为null
concat 字符串拼接函数
concat里任意一个值为null,结果均为null,可以利用这个函数来绑定维度,用于去重统计或是group by功能
补全无日期记录的数据
目前业务的需求是需要查看每天的情况,如果当日数据库没有任何记录,普通状况下当天的日期值是缺失的,导致图像会不连续,现在需要补全全部日期,使那些原本无当日记录的数据与上次有记录的数据对齐= 。 =
目前的做法是需要创建一个有连续日期的表格,使得待补充的数据表与之进行关联,比如统计累计进行中活动的话可以通过
1 | all_day >= 活动开始时间 and all_day <= 活动结束时间 |
来将所有活动的日期补全,使在活动周期内的每天都有该记录
unpivot函数,将列融成行(列转行)
1 | SELECT sales,quarter FROM `表名` |
pivot函数,行转列
与上述功能相反
lag/lead函数跳过指定值的方法(求距离当前最近时间的不为某指定值的字段)
思路是可以使用lead和lag分别获得上一个/下一个非空值,oracle中的函数可以使用参数ignore nulls,但是BQ貌似不支持,主要思路:
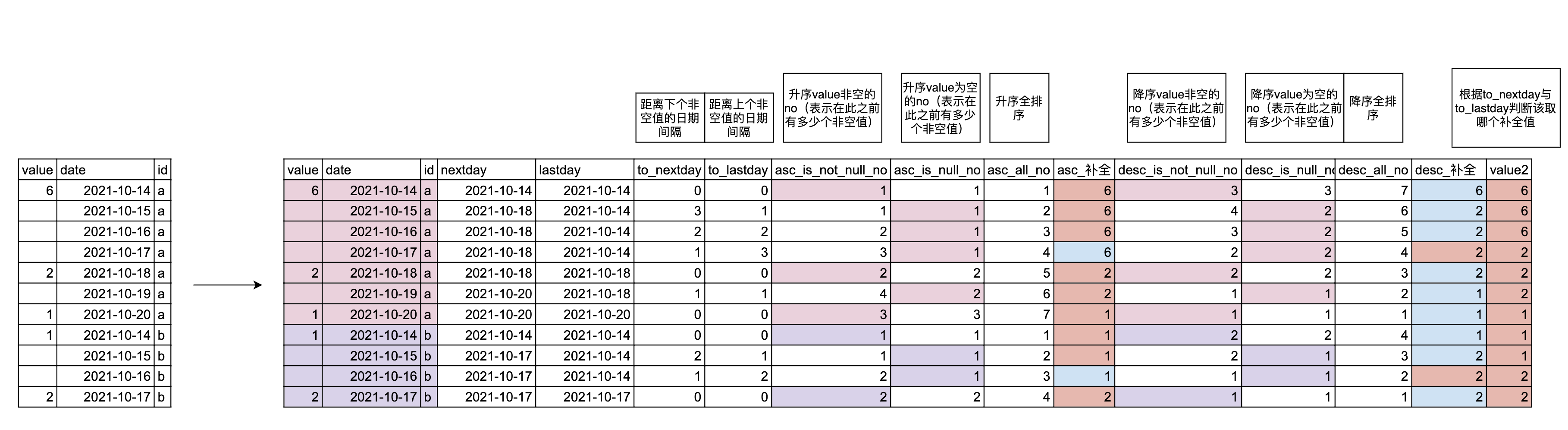
贴上代码:
1 | with data0 as ( |